3. Create Index
Before creating the index let's describe the dataset and insert entries.
Sample Dataset
In this project you will use a simple dataset describing movies, for now, all records are in English. You will learn more about other languages in another tutorial.
A movie is represented by the following attributes:
movie_id: The unique ID of the movie, internal to this databasetitle: The title of the movie.plot: A summary of the movie.genre: The genre of the movie, for now a movie will only have a single genre.release_year: The year the movie was released as a numerical value.rating: A numeric value representing the public's rating for this movie.votes: Number of votes.poster: Link to the movie poster.imdb_id: id of the movie in the IMDB database.
Key and Data structure
As a Redis developer, one of the first things to look when building your application is to define the structure of the key and data (data design/data modeling).
A common way of defining the keys in Redis is to use specific patterns in them. For example in this application where the database will probably deal with various business objects: movies, actors, theaters, users, ... we can use the following pattern:
business_object:key
For example:
movie:001for the movie with the id 001user:001the user with the id 001
and for the movies information you should use a Redis Hash.
A Redis Hash allows the application to structure all the movie attributes in individual fields; also Redis Stack will index the fields based on the index definition.
Insert Movies
It is time now to add some data into your database, let's insert a few movies, using redis-cli or RedisInsight.
Once you are connected to your Redis instance run the following commands:
> HSET movie:11002 title "Star Wars: Episode V - The Empire Strikes Back" plot "After the Rebels are brutally overpowered by the Empire on the ice planet Hoth, Luke Skywalker begins Jedi training with Yoda, while his friends are pursued by Darth Vader and a bounty hunter named Boba Fett all over the galaxy." release_year 1980 genre "Action" rating 8.7 votes 1127635 imdb_id tt0080684
> HSET movie:11003 title "The Godfather" plot "The aging patriarch of an organized crime dynasty transfers control of his clandestine empire to his reluctant son." release_year 1972 genre "Drama" rating 9.2 votes 1563839 imdb_id tt0068646
> HSET movie:11004 title "Heat" plot "A group of professional bank robbers start to feel the heat from police when they unknowingly leave a clue at their latest heist." release_year 1995 genre "Thriller" rating 8.2 votes 559490 imdb_id tt0113277
> HSET "movie:11005" title "Star Wars: Episode VI - Return of the Jedi" genre "Action" votes 906260 rating 8.3 release_year 1983 plot "The Rebels dispatch to Endor to destroy the second Empire's Death Star." ibmdb_id "tt0086190"
Now it is possible to get information from the hash using the movie ID. For example if you want to get the title, and rating execute the following command:
> HMGET movie:11002 title rating
1) "Star Wars: Episode V - The Empire Strikes Back"
2) "8.7"
And you can increment the rating of this movie using:
> HINCRBYFLOAT movie:11002 rating 0.1
"8.8"
But how do you get a movie or list of movies by year of release, rating or title?
One option, would be to read all the movies, check all fields and then return only matching movies; no need to say that this is a really bad idea.
Nevertheless this is where Redis developers often create custom secondary indexes using SET/SORTED SET structures that point back to the movie hash. This needs some heavy design and implementation.
This is where Search and Query in Redis Stack can help, and why it was created.
Search & Indexing
Redis Stack greatly simplifies this by offering a simple and automatic way to create secondary indices on Redis Hashes. (more datastructure will eventually come)
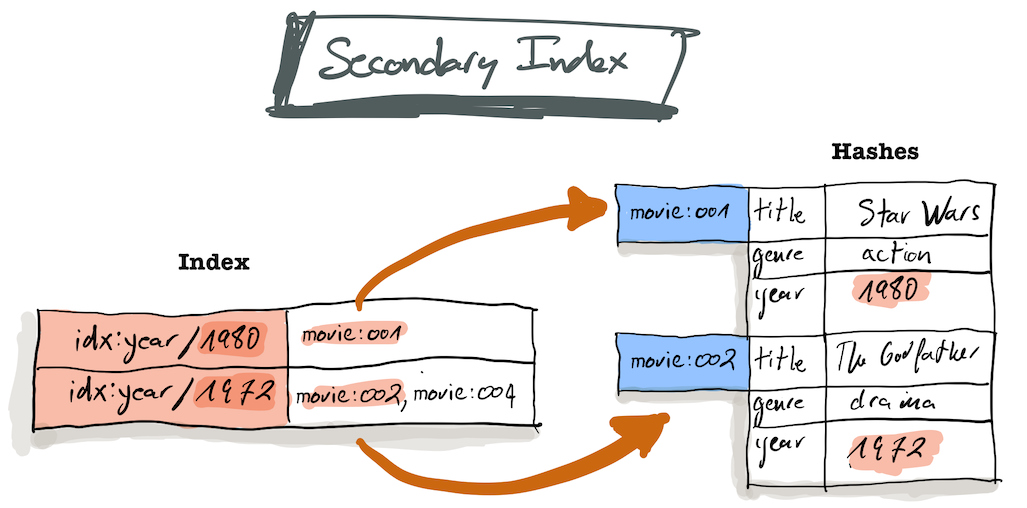
When using Redis Stack, if you want to query on a field, you must first index that field. Let's start by indexing the following fields for our movies:
- Title
- Release Year
- Rating
- Genre
When creating a index you define:
- which data you want to index: all hashes with a key starting with
movies - which fields in the hashes you want to index using a Schema definition.
Warning: Do not index all fields
Indexes take space in memory, and must be updated when the primary data is updated. So create the index carefully and keep the definition up to date with your needs.
Create the Index
Create the index with the following command:
> FT.CREATE idx:movie ON hash PREFIX 1 "movie:" SCHEMA title TEXT SORTABLE release_year NUMERIC SORTABLE rating NUMERIC SORTABLE genre TAG SORTABLE
Before running some queries let's look at the command in detail:
FT.CREATE: creates an index with the given spec. The index name will be used in all the key names so keep it short.idx:movie: the name of the indexON hash: the type of structure to be indexed.PREFIX 1 "movie:": the prefix of the keys that should be indexed. This is a list, so since we want to only index movie:* keys the number is 1. Suppose you want to index movies and tv_show that have the same fields, you can use:PREFIX 2 "movie:" "tv_show:"SCHEMA ...: defines the schema, the fields and their type, to index, as you can see in the command, we are using TEXT, NUMERIC and TAG, and SORTABLE parameters.
You can find information about the FT.CREATE command in the documentation.
You can look at the index information with the following command:
> FT.INFO idx:movie